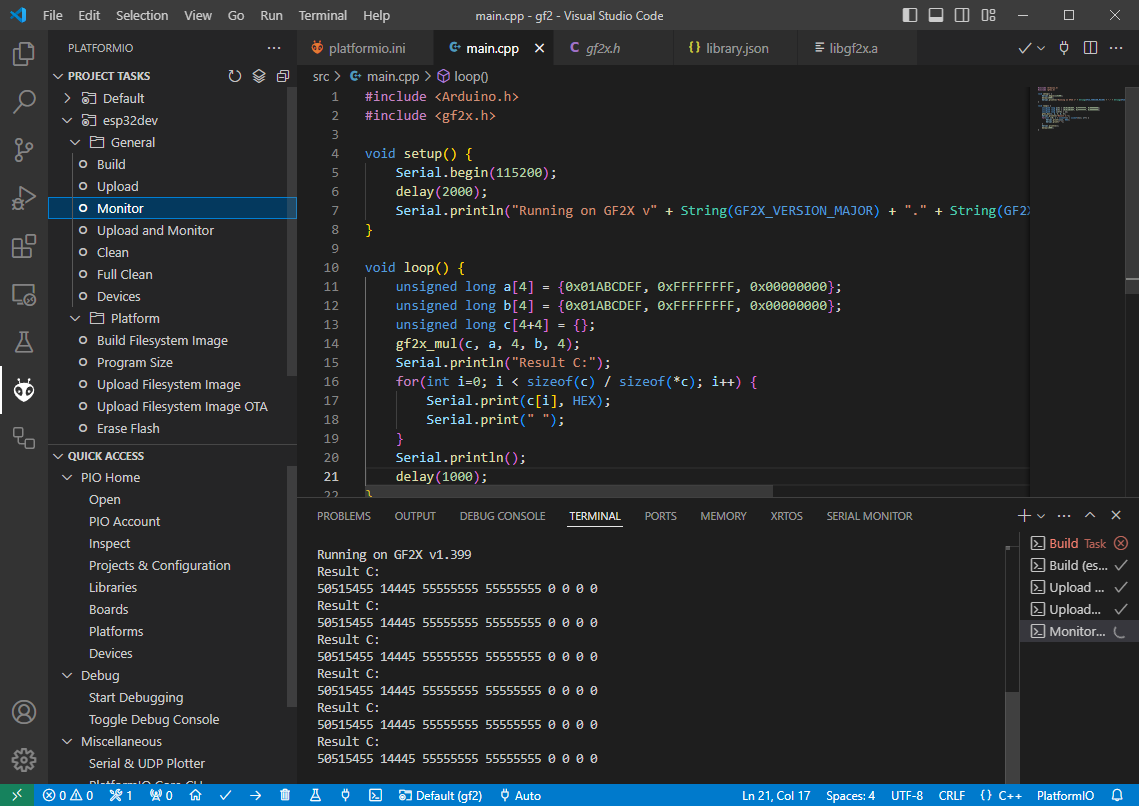
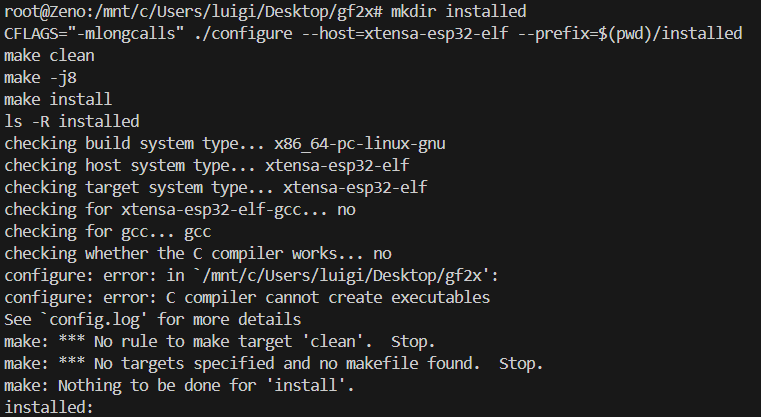
Hi all, is there by any chance a library that can be used on esp32 that allows me to use the vect_mul() function of gf2x (x86 library for computation)?
I tried to make several custom versions:
// vect_mul function to multiply two polynomials on GF(2)
void vect_mul(uint64_t *res, const uint64_t *a, const uint64_t *b, size_t len) {
mbedtls_mps A, B, R;
// Initialize the MPI variables
mbedtls_mpi_init(&A);
mbedtls_mpi_init(&B);
mbedtls_mpi_init(&R);
// Load the data into polynomials A and B.
// Since mbedTLS works with byte arrays, we need to convert uint64_t to binary strings
for (int i = 0; i < len; i++) {
// Add each uint64_t to MPI number A and B (little-endian)
mbedtls_mpi_shift_l(&A, 64); // Left shift 64 bits to make room
mbedtls_mpi_shift_l(&B, 64);
mbedtls_mpi_add_int(&A, &A, a[len - i - 1]); // Adds 'a' to A
mbedtls_mpi_add_int(&B, &B, b[len - i - 1]); // Adds 'b' to B
}
// Multiplication of polynomials A and B over GF(2)
mbedtls_mpi_mul_mpi(&R, &A, &B); // Multiplication between A and B
// Extract the result into the res buffer
for (int i = 0; i < 2 * len; i++) {
res[i] = 0; // Initialize the result
}
// Extract the result from the first 2*len uint64_t and assign it to res
for (int i = 0; i < 2 * len; i++) {
uint64_t temp = 0;
// Get 64 bits from the result and move it properly
mbedtls_mpi_write_binary(&R, (unsigned char *)&temp, sizeof(temp));
res[2 * len - i - 1] = temp;
mbedtls_mpi_shift_r(&R, 64); // Right shift to get the next 64 bits
}
// Clean up the memory
mbedtls_mpi_free(&A);
mbedtls_mpi_free(&B);
mbedtls_mpi_free(&R);
}
void vect_mul(uint64_t *res, const uint64_t *a, const uint64_t *b, size_t len) {
// Initialize the result to zero
memset(res, 0, 2 * len * sizeof(uint64_t));
// Bit-by-bit polynomial multiplication in GF(2)
for (size_t i = 0; i < len * 64; i++) {
uint64_t bit_a = (a[i / 64] >> (i % 64)) & 1; // Get the i-th bit of 'a'
if (bit_a) {
for (size_t j = 0; j < len; j++) {
res[i / 64 + j] ^= b[j] << (i % 64); // XOR and shift
if (i % 64 != 0 && (i / 64 + j + 1) < 2 * len) {
res[i / 64 + j + 1] ^= b[j] >> (64 - (i % 64)); // Extra shift
}
}
}
These functions generate output that is equivalent to but different from what the original library gives on x86 systems.
Does anyone have any advice?
Thanks for reading!