As expected for this specific code, since debug code is not optimized code… -Og vs -Os makes a lot of difference.
debug_build_flags, by default -Og -g2 -ggdb2, are applied, as opposed to the standard -Os. This produces heavily different and slower microcode. That’s the entire point of optimizing code for debugability vs fast code.
Again, not related to archiving.
It disables it for libraries in lib/ and lib_deps, not for the framework code. That will always be archived.
As expected for this specific code
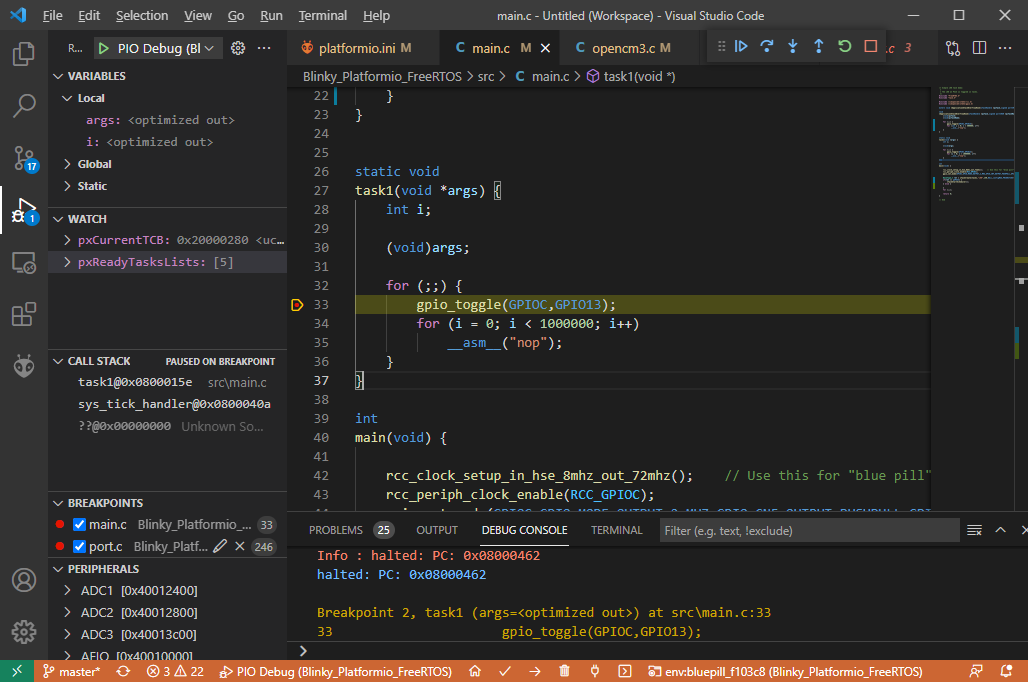
What I mean by this is that if you look at the task code
static void
task1(void *args) {
int i;
(void)args;
for (;;) {
gpio_toggle(GPIOC,GPIO13);
for (i = 0; i < 1000000; i++)
__asm__("nop");
}
}
the timing is provided by a for loop with a nop inside it. In debug mode with -Og this produces
> C:\Users\Max\.platformio\packages\toolchain-gccarmnoneeabi\bin\arm-none-eabi-objdump.exe -d .\.pio\build\bluepill_f103c8\firmware.elf | grep -A20 "<task1"
08000150 <task1>:
8000150: b508 push {r3, lr}
8000152: e004 b.n 800015e <task1+0xe>
8000154: bf00 nop
8000156: 3301 adds r3, #1
8000158: 4a04 ldr r2, [pc, #16] ; (800016c <task1+0x1c>)
800015a: 4293 cmp r3, r2
800015c: ddfa ble.n 8000154 <task1+0x4>
800015e: f44f 5100 mov.w r1, #8192 ; 0x2000
8000162: 4803 ldr r0, [pc, #12] ; (8000170 <task1+0x20>)
8000164: f000 fcc6 bl 8000af4 <gpio_toggle>
8000168: 2300 movs r3, #0
800016a: e7f5 b.n 8000158 <task1+0x8>
800016c: 000f423f .word 0x000f423f
8000170: 40011000 .word 0x40011000
As compared to release mode
08000150 <task1>:
8000150: b510 push {r4, lr}
8000152: 4c05 ldr r4, [pc, #20] ; (8000168 <task1+0x18>)
8000154: f44f 5100 mov.w r1, #8192 ; 0x2000
8000158: 4620 mov r0, r4
800015a: f000 fc72 bl 8000a42 <gpio_toggle>
800015e: 4b03 ldr r3, [pc, #12] ; (800016c <task1+0x1c>)
8000160: bf00 nop
8000162: 3b01 subs r3, #1
8000164: d1fc bne.n 8000160 <task1+0x10>
8000166: e7f5 b.n 8000154 <task1+0x4>
8000168: 40011000 .word 0x40011000
800016c: 000f4240 .word 0x000f4240 ;hex 1,000,000
You can see that the critical part that is executed 1 million times in the debug version is
8000154: bf00 nop
8000156: 3301 adds r3, #1
8000158: 4a04 ldr r2, [pc, #16] ; (800016c <task1+0x1c>)
800015a: 4293 cmp r3, r2
800015c: ddfa ble.n 8000154 <task1+0x4>
which is, nop-ing, adding one to a register (counter), then loading the constant 1000000 value from a location in RAM, comparing those two, and if they’re not equal, jump back to the nop location.
The optimized version does
800015e: 4b03 ldr r3, [pc, #12] ; (800016c <task1+0x1c>)
8000160: bf00 nop
8000162: 3b01 subs r3, #1
8000164: d1fc bne.n 8000160 <task1+0x10>
this only loads the value 1000000 from flash once into r3, then does a nop, then subtracts one from r3 and checks if it’s 0 (a side effect of the subs instruction is that it sets the not-equal / non-zero flags after the subtraction). So the inner loop only operates on registers and is 3 instructions long (the load instruction ins only executed once), as compared to 5 instructions in every inner loop with a load from Flash (slooow…). So, this will easily be faster in release version than in the debug version.
You can see that the debug version perfoms the blinky as fast as the release version if the compiler is allowed to optimize the loops. Change the function to
#pragma GCC push_options
#pragma GCC optimize ("-Os")
static void
task1(void *args) {
int i;
(void)args;
for (;;) {
gpio_toggle(GPIOC,GPIO13);
for (i = 0; i < 1000000; i++)
__asm__("nop");
}
}
#pragma GCC pop_options
and upload it in release and debug mode. You will see that the speed is now identical.
Of course, you do not want to rely on nop loops to get the timing right. That’s what you RTOS is for.
You will see that if you write the function simply as
static void
task1(void *args) {
int i;
(void)args;
for (;;) {
gpio_toggle(GPIOC,GPIO13);
vTaskDelay(pdMS_TO_TICKS(100));
}
}
then the FreeRTOS scheduler will put your thread to sleep for 100ms (as provided by the SysTick), and that is pretty immune to code optimization level. Upload it in release and debug mode, and you will observe no perceivable difference between them.
Of course internally, the FreeRTOS functions will be a little bit slower to execute since it’s still unoptimized code in debug mode, but that will now be negligble as not the entire sleep time is stretched by the unoptimized code (as it was in every iteration of the 1,000,000 iterations of the NOP loop before), the timing is provided by the timer.